日志收集
两种方式
这里是将pod中的日志收集,放到一个指定的地方
首先是将程序中的日志能采集到,大致有两种方式
- 通过插件将日志重定向到指定目的地
- 用辅助程序采集pod中日志,并重定向
两种方式处理如下
- 都是将日志写到一个指定的地方
- 区别是由程序本身去做,还是由额外的程序去捕获
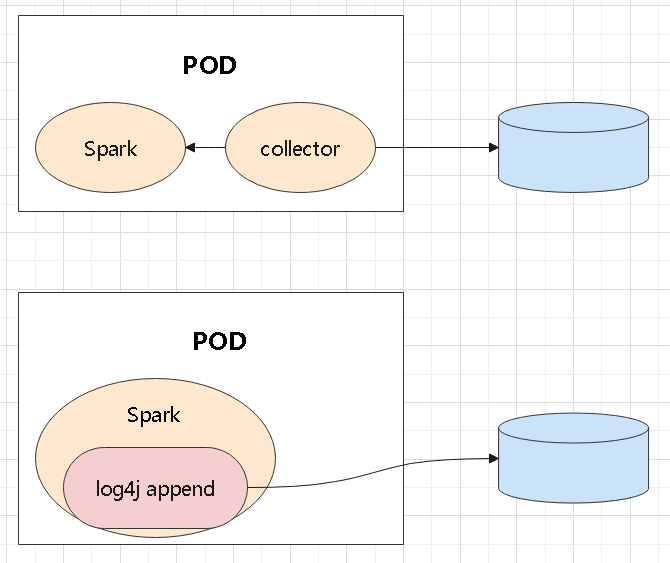
日志扩展
- 比如 log4j,需要实现一个自定义的 appender
- 修改配置文件,用 log4j 的自定义扩展,写入指定的目的地
配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
rootLogger.level = info
rootLogger.appenderRef.customRolling.ref = myRollingFileAppender
# Define the custom rolling appender
appender.myRollingFileAppender.type = MyRollingFile
appender.myRollingFileAppender.name = myRollingFileAppender
appender.myRollingFileAppender.fileName = cyber.log
appender.myRollingFileAppender.filePattern = cyber-%d{yyyy-MM-dd}.%i.log
appender.myRollingFileAppender.layout.type = PatternLayout
appender.myRollingFileAppender.layout.pattern = %d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
appender.myRollingFileAppender.policies.type = Policies
appender.myRollingFileAppender.policies.size.type = SizeBasedTriggeringPolicy
appender.myRollingFileAppender.policies.size.size = 10MB
appender.myRollingFileAppender.strategy.type = DefaultRolloverStrategy
|
对于应用程序来说,需要增加一些启动参数
- 记录角色, -Drole=spark,或者 flink
- 记录 application_id、executor_id
- 以及路径前缀(将日志写入到哪里)
- 注意这种模式下,一般需要将日志写入到 NFS 这种共享存储
- 当程序退出后,在这个目录下写一个标志文件,表示文件退出了
- 当然,程序启动的时候,如果有这个标志文件,需要先清理掉
- 对于 System.out 和 err ,需要做重定向
处理日志
写 kafka
这里是将日志通过插件写入到kafka
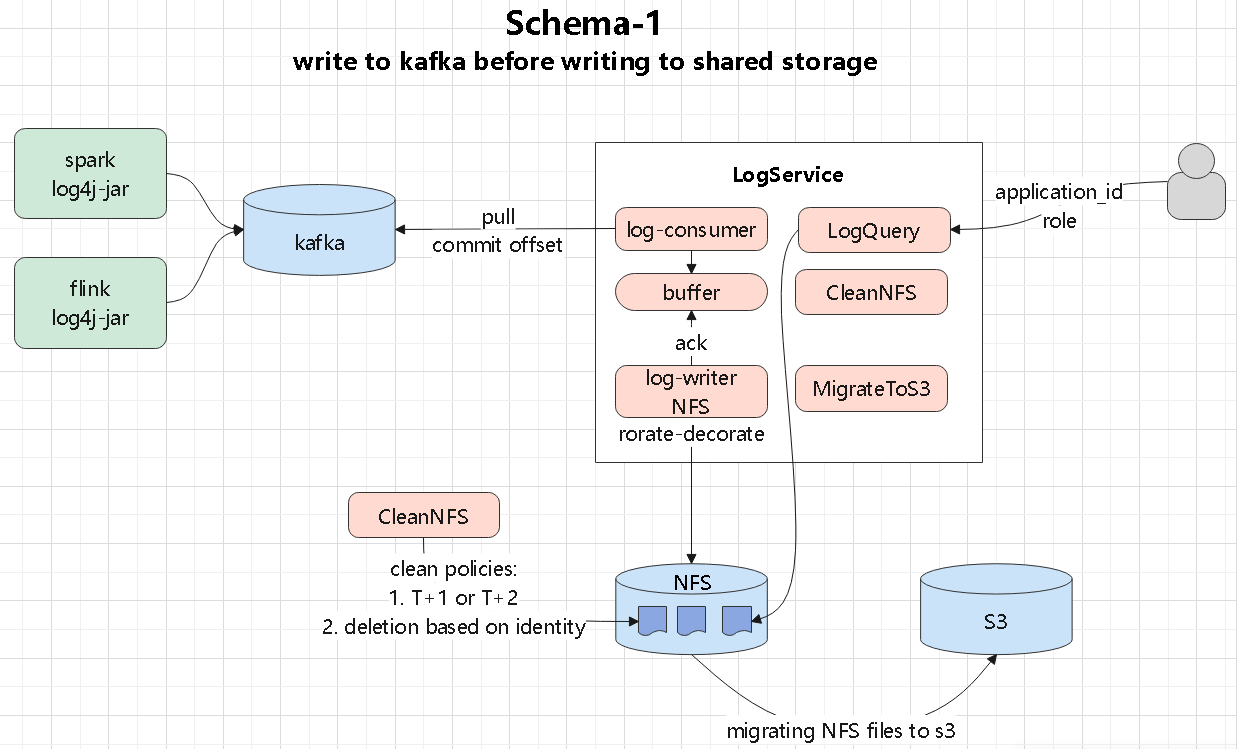
log-service
- 消费kafka,将日志写入到内部的buffer
- 后面有 writer 写入到 NFS,注意这里还要有 ack 机制
- 其他还有 日志定期清理日志,迁移到 s3 模块
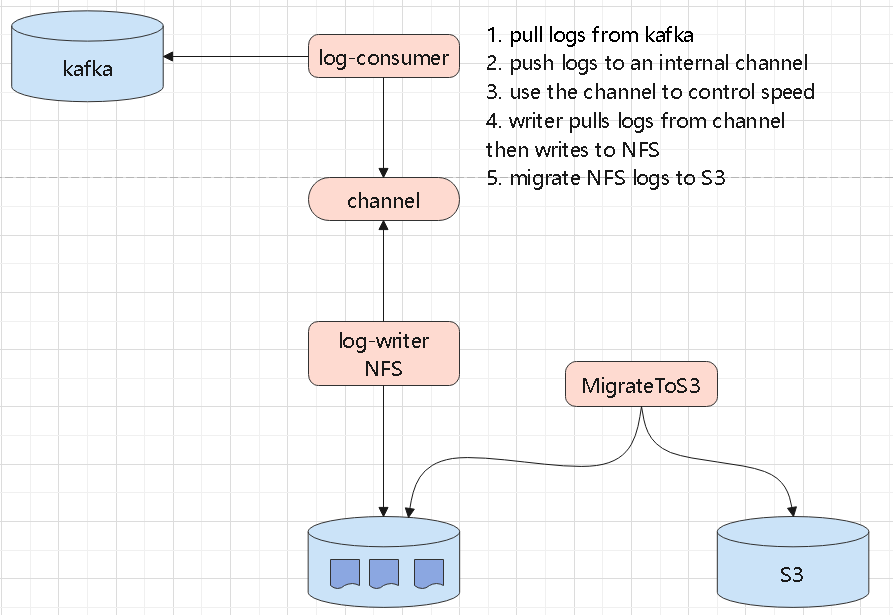
log-sumer
- 从kafka 读取日志,写入到内部的 channel 中
- 这里的 channel 可以做限流,记录等额外的功能
- 之后有另外一个 writer 负责读取 channel,将日志写入 NFS
- 同时还需要做日志轮转处理,以及 迁移到 s3
直接写共享存储
跟第一种差不多,但是少了 kafka 的处理部分
log-service
- 有一个日志查询服务,用户可以通过 application_id 来查询日志文件内容
- 为了解决单个目录下小文件过多问题,需要增加一个 hash 前缀
- 可以设置为 20,003,这是一个质数,也就是一个目录下最多有2W文件
- 目录为: hash/application_id/executor_id/xx.log
- hash 最多2W个,一天产生 10W个应用,算算可以用几十年了

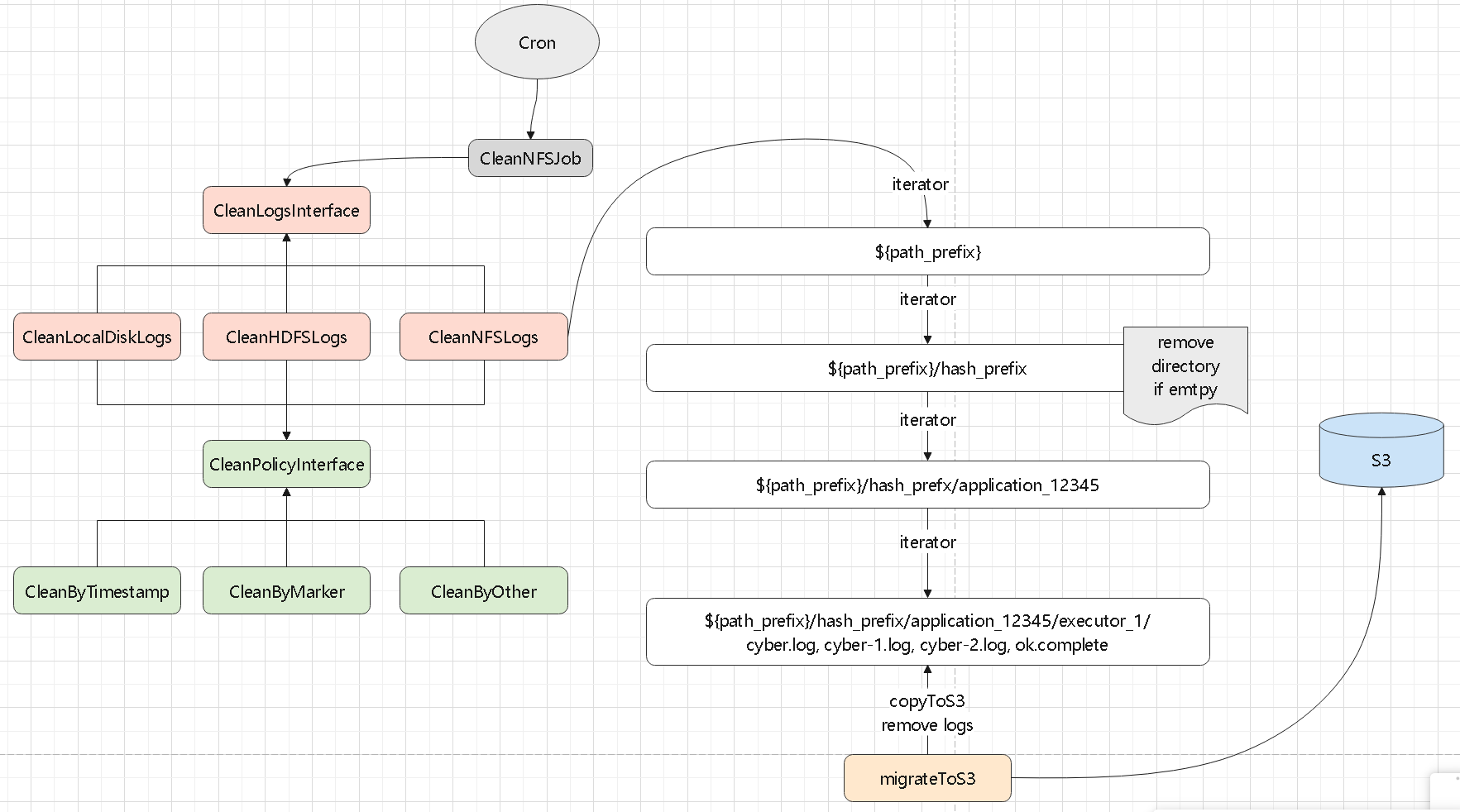
日志清理
- 一个日志清理模块,可以清理disk,NFS
- 以及清理策略,根据时间戳,可以目录下是否包括一个 标志文件来清理
- 比如: /data/spark/cluster_logs/14937/app-12345/executor-17
- 路径前缀是:/data/spark/cluster_logs,产生了 14937 这个 hash 目录
- 然后是 app-12345,清理程序根据app-12345 是否空了,来决定是否删除 app-12345
- 同样逻辑,清理下面的 driver 和 executor
- 最后将日志复制到 S3、或者 minio;这里需要先复制到 s3,再清理
- 如果复制成功,没删除,下一次处理的时候会覆盖 s3并清理文件
- 最后删除目录下的标志文件
多个节点处理
- 为防止日志太多单个节点处理不过来,可以启动多个节点
- 但多个节点可能会重复处理一个文件,所以每个节点处理前
- 先获取文件列表,然后 shuffle一次,这样每个节点处理的目录就不一样了,这种方式最简单
- 也可以将文件写入 红黑树,然后转换成 一致性hash 的环形
- 根据当前的节点 hash,定位到环的一个为止,然后顺时针处理,这样每段由不同节点处理
- 虽然每个节点都遍历了全部目录,但是非自己处理的基本都是空的(被别人处理过了),所以效率会提升
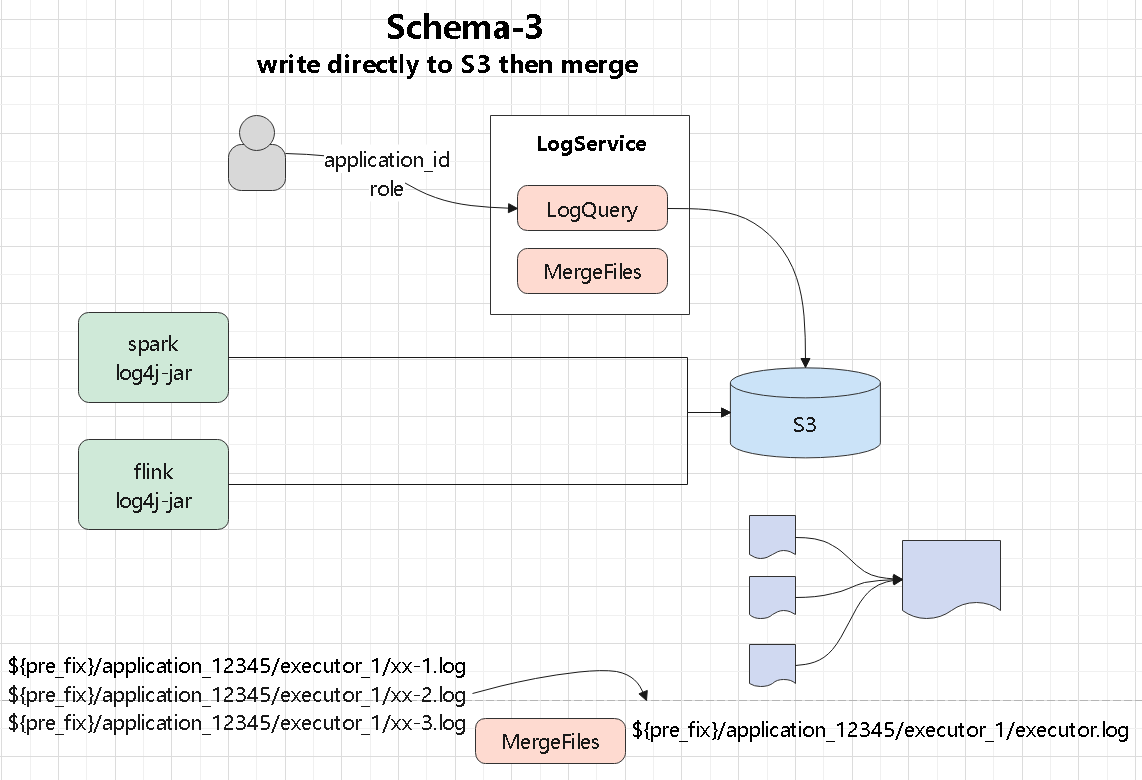
直接写 S3
这种方式比较简单
- 日志直接写入到 s3,但是会产生很多小文件
- 需要定期将小文件合并
- 同理提供query 服务,可以查询 s3 上的日志文件
- 这里查询的话会麻烦一些了,可能需要查多个 日志小文件
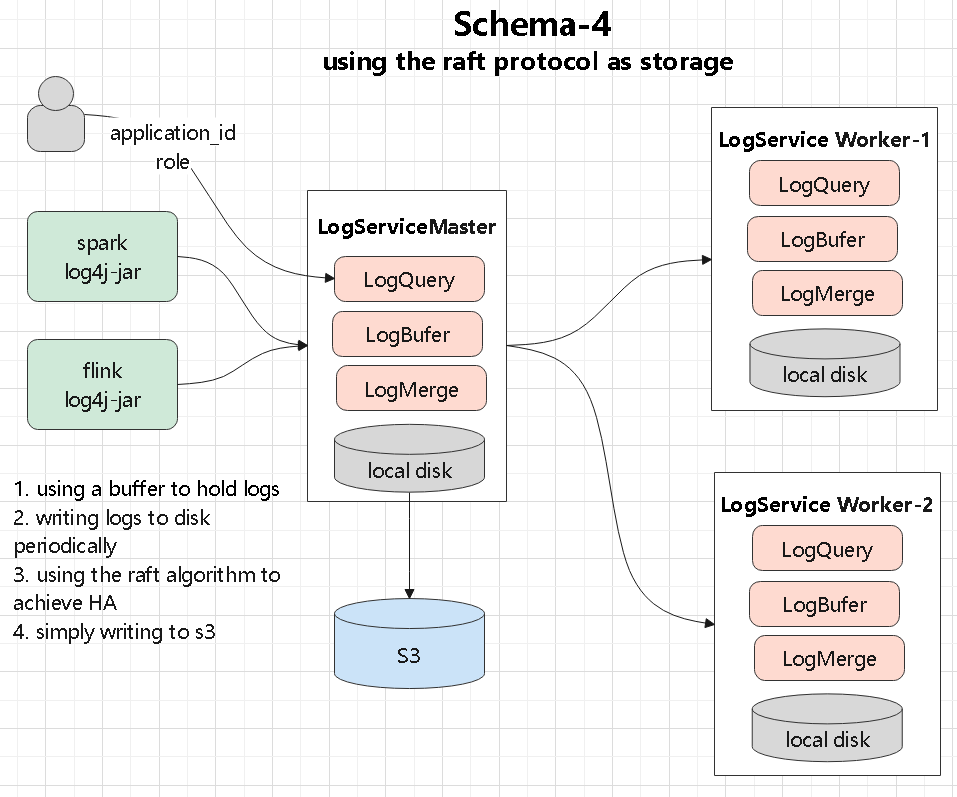
使用raft 组日志集群
这里不需要写 共享存储
- 日志写入到 log-service,这是包含一主-两从的三节点服务
- 通过 raft 实现强一致,主从同步,当主节点挂了,从节点晋升为主节点
- 这种方式不需要共享存储了,直接写本地磁盘就行了,三副本保证高可用
- 同时定期写 s3,这种方式需要处理好选主,可以用 apache 的 raft 实现
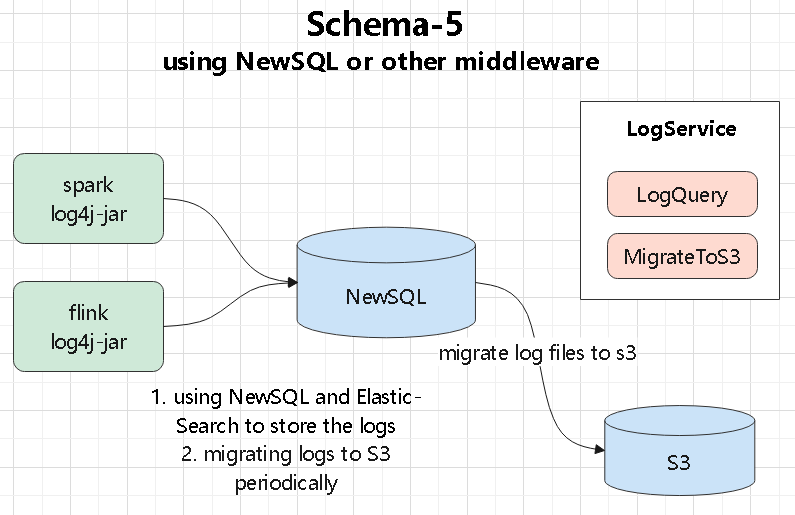
使用 NewSQL
使用 newsql
- 比如写入到 TiDB,mysql
- 或者写入到 ES,直接用这个中间设备做查询,还可以做模糊匹配查询
- 这种模式的查询能力强了,但是强依赖了一个中间件
- 同样也需要定期写入到 s3
总结
对比
- 实际每种方案最终都会写 s3,但方案-3,会带来很多延迟,并不好
- 方案-4 使用了三个节点,成本会升高,另外开发难度很大
- 方案-5 需要强使用一个中间件,依赖性太大了
- 综合来说,方案-1、方案-2更合适
- 方案1、方案2实际都是写入了共享存储,所以后面都是类似的
- 方案1 先写 kafka,而其他程序如分析类的,可以读kafka 做更多事情,所以方案-1的扩展性可能更强
调度
Spark端
一个完整的 spark-submit 参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
./spark-submit \
--master k8s://https://<k8s-address>:<k8s-port> \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.container.image=spark-image:3.5.0-log4jext \
--conf spark.kubernetes.authenticate.submission.caCertFile=/etc/kubernetes/pki/ca.crt \
--conf spark.kubernetes.authenticate.submission.clientKeyFile=/etc/kubernetes/pki/apiserver-kubelet-client.key \
--conf spark.kubernetes.authenticate.submission.clientCertFile=/etc/kubernetes/pki/apiserver-kubelet-client.crt \
--conf spark.kubernetes.authenticate.driver.caCertFile=/etc/kubernetes/pki/ca.crt \
--conf spark.kubernetes.authenticate.driver.clientKeyFile=/etc/kubernetes/pki/apiserver-kubelet-client.key \
--conf spark.kubernetes.authenticate.driver.clientCertFile=/etc/kubernetes/pki/apiserver-kubelet-client.crt \
--conf spark.kubernetes.namespace=test \
--conf spark.kubernetes.driverEnv.SPARK_PREFIX_DIR=/custom/path \
--conf spark.executorEnv.SPARK_PREFIX_DIR=/custom/path \
--conf spark.kubernetes.driverEnv.SPARK_EXECUTOR_ID=driver \
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.data.options.claimName=my-pvc \
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.data.mount.path=/custom/path \
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.data.mount.readOnly=false \
--conf spark.kubernetes.executor.volumes.persistentVolumeClaim.data.options.claimName=my-pvc \
--conf spark.kubernetes.executor.volumes.persistentVolumeClaim.data.mount.path=/custom/path \
--conf spark.kubernetes.executor.volumes.persistentVolumeClaim.data.mount.readOnly=false \
--conf spark.driver.extraJavaOptions='-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005
-Dlog4j.configurationFile=/opt/spark/work-dir/log4j2.properties' \
--conf spark.executor.extraJavaOptions='-Dlog4j.configurationFile=/opt/spark/work-dir/log4j2.properties' \
--conf spark.kubernetes.container.image.pullPolicy=Always \
local:///opt/spark/examples/jars/spark-examples_2.12-3.5.2.jar
|
Spark 的 driver 和 executor 都需要设置一些 ENV 参数:
- SPARK_EXECUTOR_ID ,driver端需要手动设置,executor 是自动设置上的
- SPARK_APPLICATION_ID ,driver 和 executor 都是自动设置上的
- SPARK_PREFIX_DIR ,driver 和 executor 都需要手动设置上