Lakehouse A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics
原文 https://15721.courses.cs.cmu.edu/spring2023/papers/02-modern/armbrust-cidr21.pdf
背景
DataBricks 建立了LakeHouse,有这么几个特点
- 开放的直接访问的格式,如Parquet、ORC
- 支持机器学习、数据科学等各种场景
- 最先进的性能
为什么要搞这个,从历史角度看
- 第一代数仓就是将数据灌入到 中央的数据仓库中,BI等工具做分析
- 第一代数仓是计算和存储紧耦合的,而且要提前按照峰值的价格购买配置
- 第二代是 Hadoop出现之后,数据和计算分离了,放到廉价的存储智商
- 之后云存储出现了,可靠性,扩展性更高,更便宜,但本质上跟 Hadoop 差不多
- 二代的架构是两层,数据先 ETL 到数据湖中,然后再 ETL 到数据仓库中
两层架构的问题
- 数据回来倒腾,导致可靠性降低
- 因为几次倒腾,时效性也降低了
- 对机器学习,数据科学等复杂场景,数据仓库支持不了
- 费用增加了,数据需要存两份,而且商业数仓都是私有格式,想迁移出来成本都很高
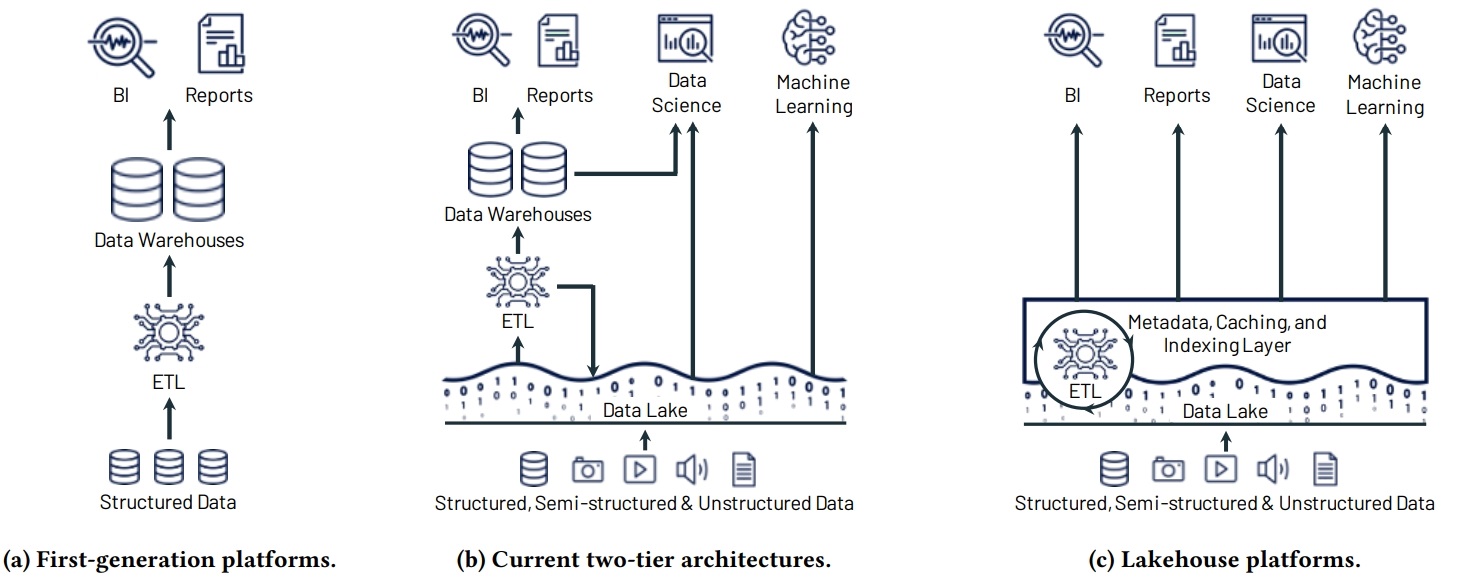
Figure 1: Evolution of data platform architectures to today’s two-tier model (a-b) and the new Lakehouse model (c).
架构
LakeHouse 就是用来解决上述问题的,关键点是增加了一个 元数据层,这层是在存储文件 S3,parquet之上的
有了这个元数据管理层,就可以实现 ACID,MVCC等功能了
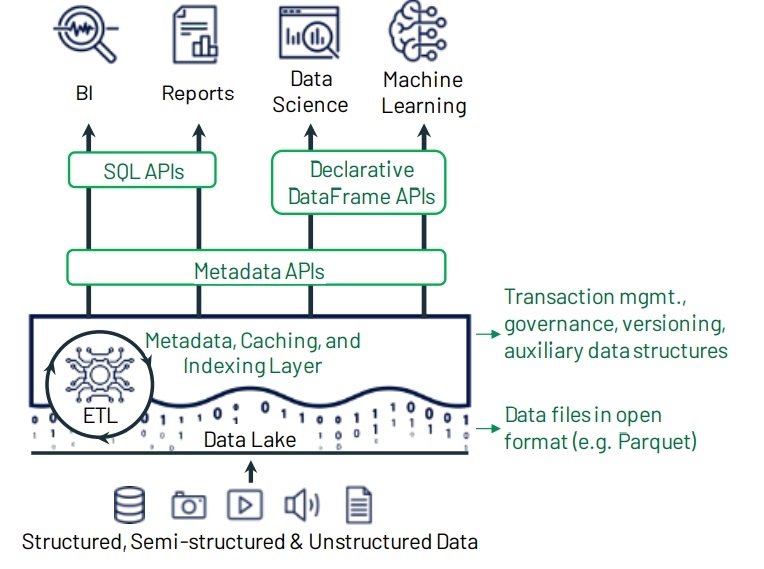
Figure 2: Example Lakehouse system design, with key components shown in green. The system centers around a metadata layer such as Delta Lake that adds transactions, versioning, and auxiliary data structures over files in an open format, and can be queried with diverse APIs and engines.
当然增加一个元数据层只是实现了 ACID,对于性能上的优化,肯定是不能改文件格式,因为他们都是开放的
开放的数据格式相当于 一种开放的API了,改了就变成私有格式了
对此的方案有很多
- 缓存,放到本地内存或者SSD
- 辅助数据结构,如日志中包含了min、max信息可以实现skip数据,还有bloom过滤器等
- 统计信息
- 数据布局优化,独立维度、空间曲线Z-order、局部性访问的多维空间希尔伯特曲线
使用了这些优化方式之后,LakeHouse 可以跟闭源的数仓提供类似的性能,而其数据格式是基于开放的
另外使用 DataFrame API,通过各种延迟操作,可以做一进步的优化,加速机器学习、数据分析等场景
像Hive 就是将这些底层存储做了封装,使的他们称为数据表的一部分,实现了 ACID
相关产品
- 2016年 DataBricks 搞出了 Delta-lake
- 之后奈非搞了Ice-Berg
- Uber弄出了Hudi
比如将原始的Paruquet 文件导入到 delta-lake 仅仅是记录日志信息,数据不做拷贝,但增加了数据管理的能力
元数据的其他一些好处
- 记录了哪些原始 S3 文件 是表的一部分
- 比如将原始的Paruquet 文件导入到 delta-lake 仅仅是记录日志信息,数据不做拷贝,但增加了数据管理的能力
- 审计管理
- 访问控制
一些开放的问题
- 使用 S3 这种对象存储来存储日志,可靠性很好,但是延迟很高,所以限制了每秒中的事务数
- 理论上用更快的存储来保持事务日志会更好
- 目前 三个数据湖格式 都是只支持单表事务,如果扩展成多表事务也是一个问题
- 考虑为硬件、更好的优化性能,设计一种新的数据格式,并且作为开放的格式
- 多种缓存策略、辅助数据结构、数据布局优化,这些实现方式有很多,哪些或哪些组合对某些数据集更有效,也是一个研究话题
- 设计无服务的计算,以及最大限度的减少延迟
通过缓存、辅助数据结构、数据布局这三种优化之后,跟 4种 云上的数仓对比
可以看到 LakeHouse 还是很有竞争力的
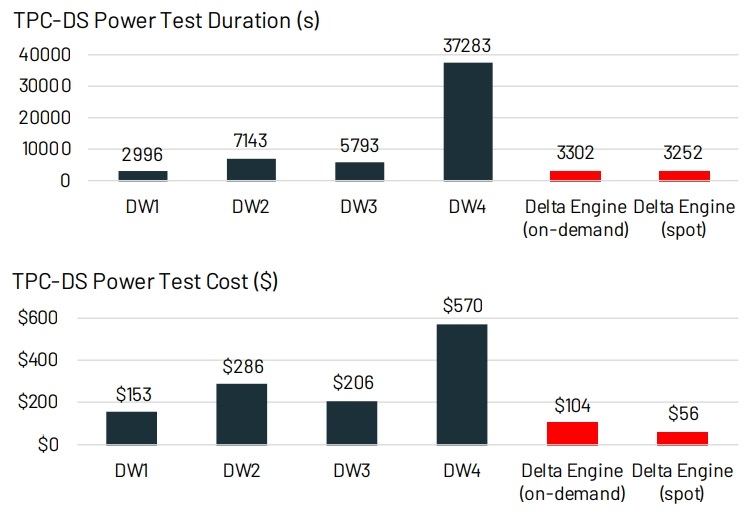
Figure 3: TPC-DS power score (time to run all queries) and cost at scale factor 30K using Delta Engine vs. popular cloud data warehouses on AWS, Azure and Google Clou .
另外 DataFrame 支持 API的形式,可以更好的支持ML 等一系列更复杂的场景
并通过 DataFrame 做进一步优化
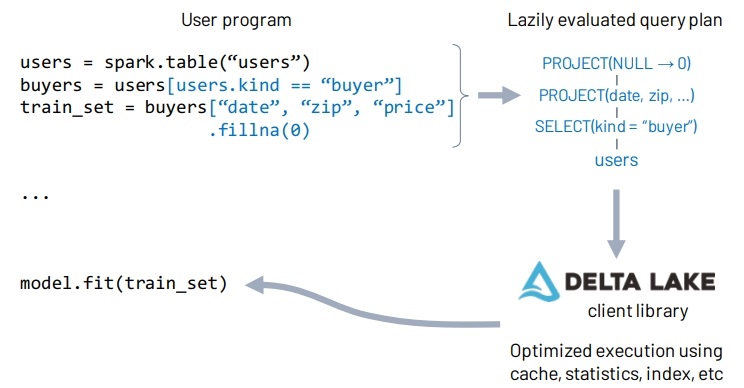
Figure 4: Execution of the declarative DataFrame API used in Spark MLlib. The DataFrame operations in user code execute lazily, allowing the Spark engine to capture a query plan for the data loading computation and pass it to the Delta Lake client library. This library queries the metadata layer to determine which partitions to read, use caches, etc.
研究问题及启示
是否有其他方式来实现 LakeHouse?
- 比如为数据仓库构建一个大规模并行服务层
- 支持高级分析工作负载的并行读取
- 但这种方式的性能可能不高,管理成本却很高
- Hive LLAP
- 不过企业仍然喜欢直接访问开放的格式,这样不会锁定某个厂商
对数据管理的影响
- 底层文件跟lakehouse 是分离的,多种文件格式 可以让企业实现多种不同目的
- 数据整合、清理工具 可以运行在lakehouse之上
- HTAP可以在 lakehouse之上搭建一层,然后方便入湖,后续HTAP 可以直接访问这些文件
- 云对象存储之上的元数据管理
- data mesh,企业的多个部门可以基于lakehouse共享数据
相关文章
相关文章
- Building An Elastic Query Engine on Disaggregated Storage
- Efficiently Compiling Efficient Query Plans for Modern Hardware
- Generating code for holistic query evaluation
- Implementing Database Operations Using SIMD Instructions
- SIMD-Scan: Ultra Fast in-Memory Table Scan using onChip Vector Processing Units