14 年工作经验,主要偏底层、中间件
有 JavaEE 应用服务器、PAAS 平台、大数据存储、大数据计算等开发经验
11 项国家发明专利
某大型 toB 企业
公司主打的湖仓一体查询引擎,作为其他产品的底座支撑
主要工作
- 参与初期版本设计(参考QuickSQL)
- 设计并开发 统一查询引擎(基于Spark和Delta Lake),支持云原生、存储计算分离架构、对接 10+ 数据源
- 扩展Spark,开发了元数据管理功能
- 设计开发 HiveServer 功能,客户端可以用 Hive JDBC 连接
- 设计开发 高可用功能(参考Kyuubi),和资源隔离功能,增加产品稳定性和多租户隔离性
- 几次客户现场支持
- 调研一些商业数据库的迁移方案 和迁移工具
- 跟 某大厂 合作,参与深度OEM合作
- 参与POC环境搭建和测试,参与数据库赛宝评测,个人通过 数据库 中级认证
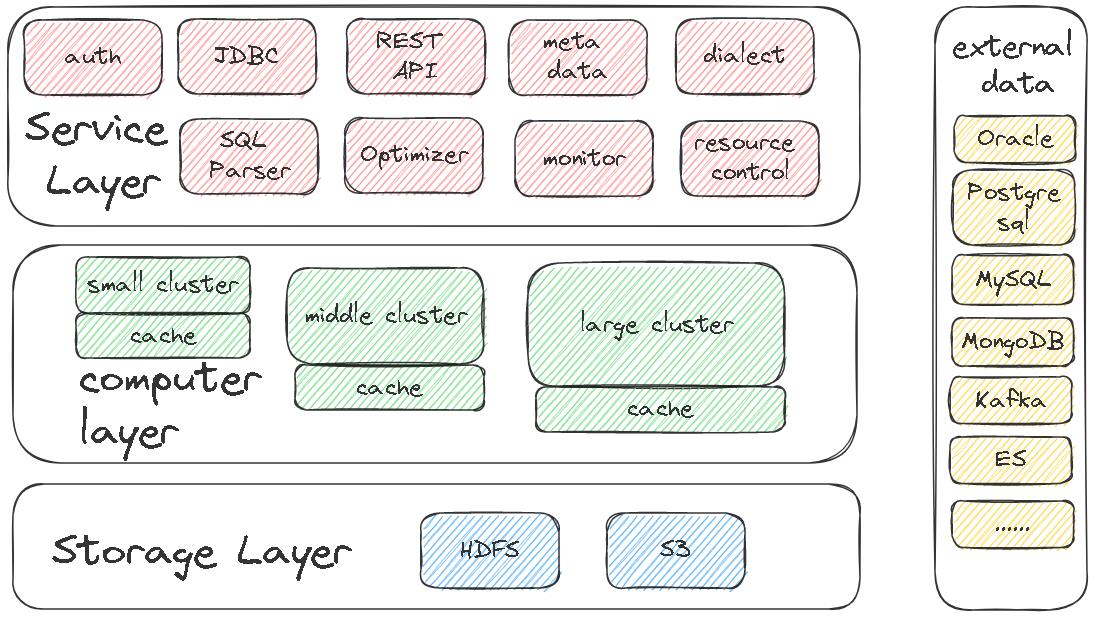
按模块划分
- 扩展了 Spark,增加了元数据管理、对接各种数据源,以及自定义的一些优化规则
- 按照集群的规模分为小、中、大版本,配合资源控制实现隔离机制
- 可以自己管理存储,存储格式为 Delta-Lake,也可以将数据存储在外部
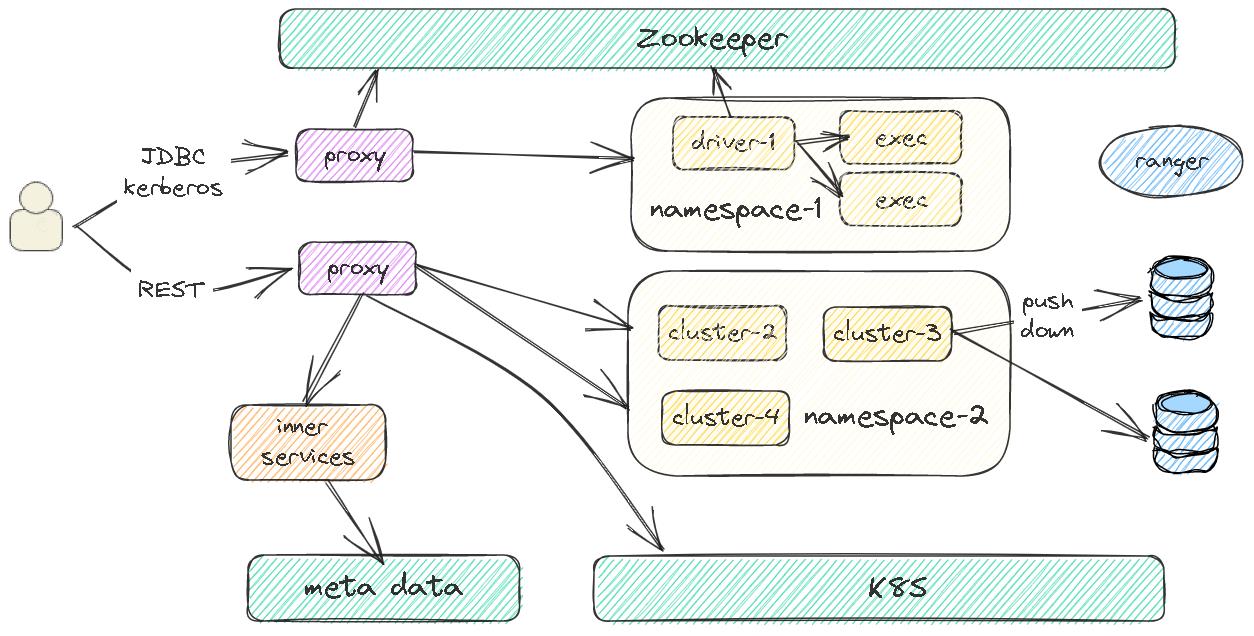
架构
- 参考了 Kyuubi,使用了两层调度,实现可高可用
- 不同集群被划分到 不同的 k8s namespace 下
- 支持权限认证,SQL 下推
Oracle CDC 同步工具
- 基于C++实现的开源项目OpenLogReplicator 做了改造
- 支持读取ASM文件,支持RAC架构,支持高可用
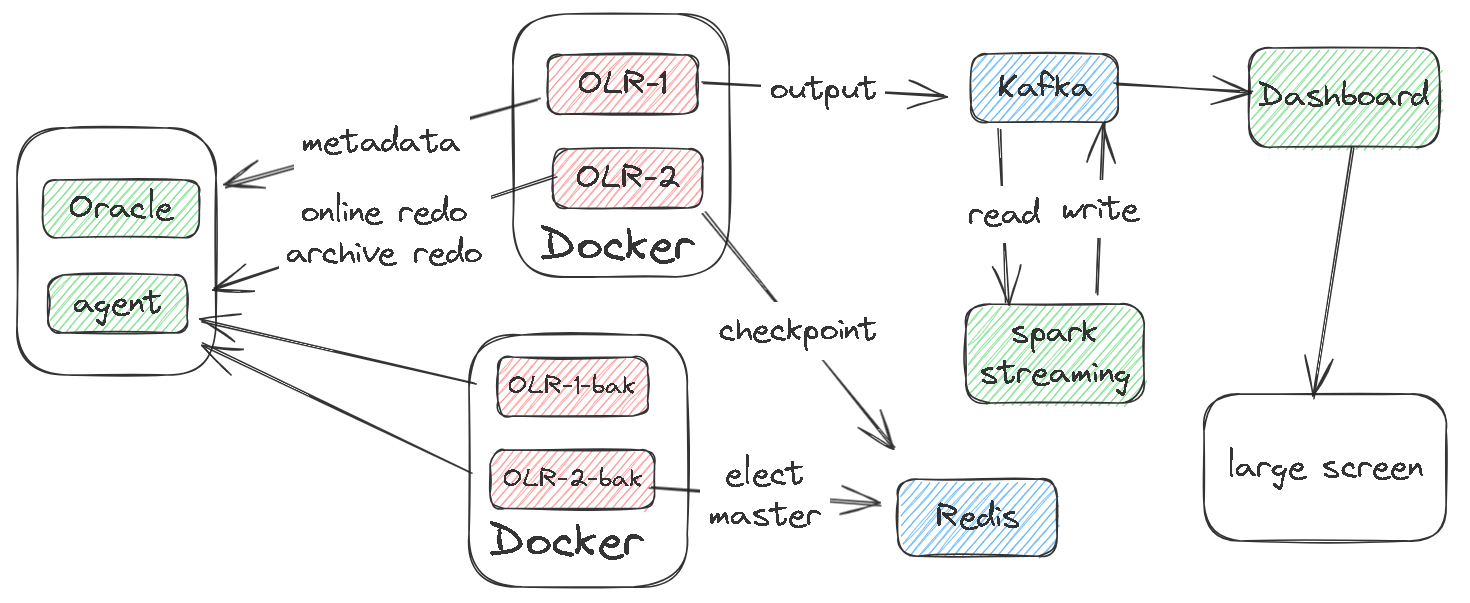
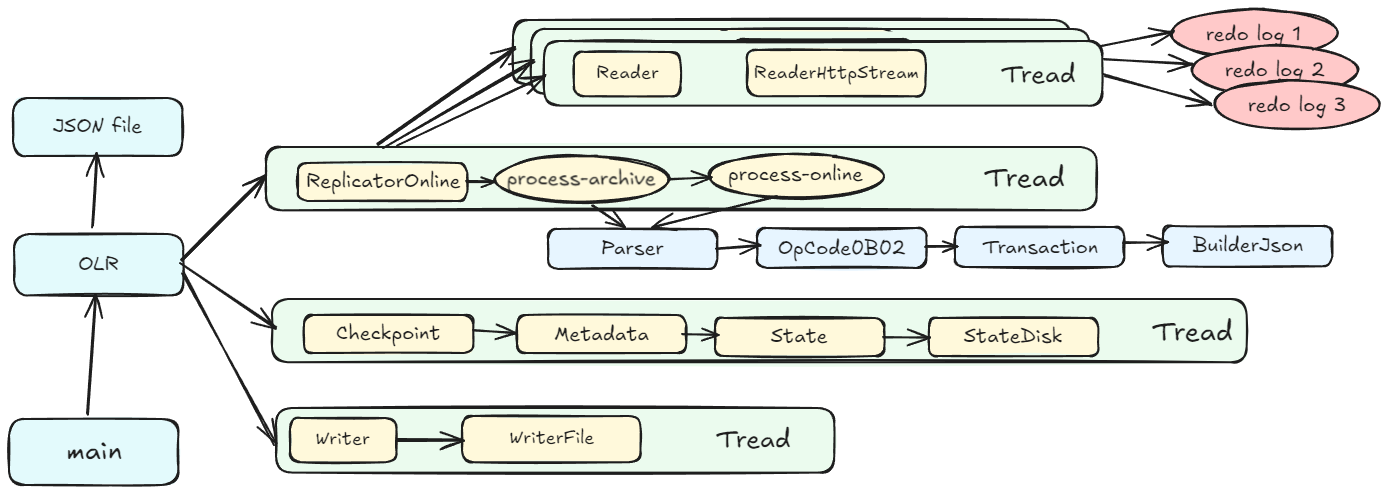
同步工具的内部细节
- 多个 reader 线程,每个线程对应于一个活跃的 redo log
- 单个解析线程,会解析archive、online redo log,然后交由 Parser类做真正的解析
- checkpoint 线程会定期记录元数据,位点信息
- 写线程拿到解析线程生成的格式化数据(json)后,推到指定的目标
某大型互联网+ 企业
一款企业内部的数据同步产品
为公司多个大业务部门内,部门间提供数据同步功能
主要工作内容
- 开发了适应公司业务需求的同步系统,大幅度减轻了之前错乱复杂的同步流程
- 持续迭代维护了系统的稳定性
- 跟其他部门的实时同步整合成一个更大的系统,之后开源出去了
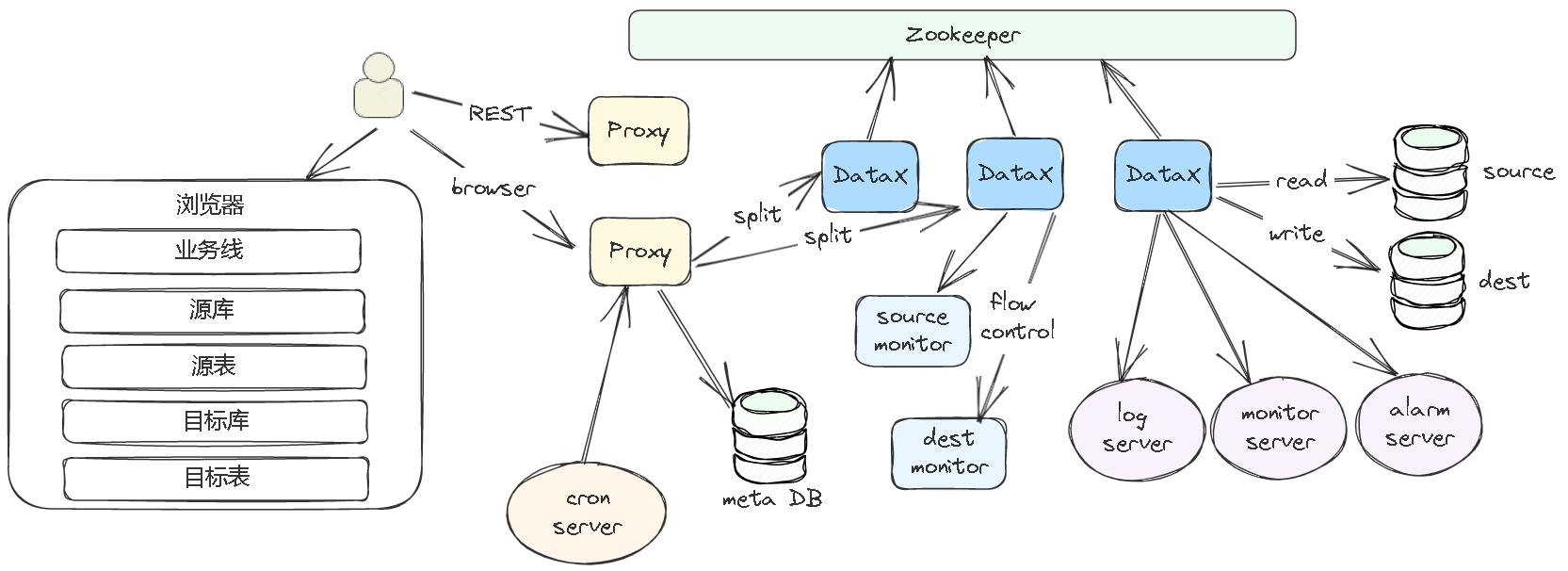
产品架构
- 用户可以通过浏览器访问,也可以通过 API 的方式调用
- Proxy 前面还有一个负载均衡,请求落到 Proxy 之后,会读取源数据库,根据数据量大小做适当拆分
- 将整个任务拆分成多个子任务,然后调用不同的 DataX 节点来读取、写入数据
- DataX 节点在写入过程中,会不断监控源节点/目标阶段状态(通过调用监控接口),来调整自身的流量
PaaS 平台
仿造谷歌 GAE 做的一款 PAAS 产品,是国内最早的 PAAS 产品
主要工作内容
- 作为核心人员,参与了从无到有的 Java 平台发展过程,是 Java 平台的最主要贡献者
- 维护了 KV 存储系统,保证了系统的稳定性
- 在经历了 10 年一见的故障后,找回了很多丢失数据,帮助平台挽回很大损失
- 工作期间有过两个创新的技术,帮助平台实现了易用性和稳定性,后将这两个创新申请了专利
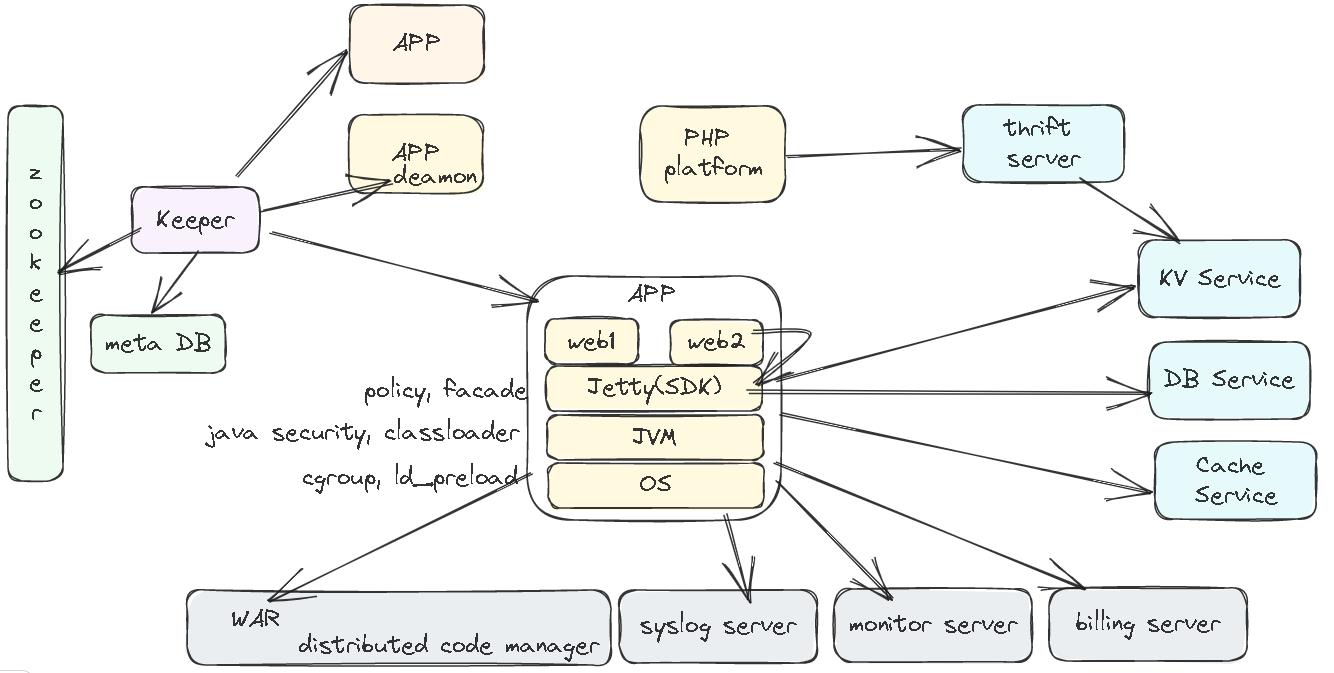
产品架构
- 基于物理机之上,部署多个 JVM,每个 JVM 之上再运行一个 Jetty,Jetty 上面部署了多个用户的应用
- 隔离策略包括了多层,每个用户单独账号读写路径分离
- 使用 Cgroup 控制资源,使用 LD_PRELOAD 给系统库打桩,JVM 方面使用 Java 自己的安全管理器
- 再往上层的 Jetty 定义了一堆安全策略,同时增加一些门面类,通过禁止对这些门面类调用放射,隔离用户和 Jetty
- Jetty 中有平台的 SDK,通过 SDK 来访问各种服务
- 运行期间会日志写入到 日志中心,将监控信息写入到监控中心,调用信息汇总到计费中心,用户 WAR 通过分布式代码管理系统导入
- 多个 APP 由 Keeper 来管理,负责启动/停止等
专利 1 原理描述
- 通过扫描hbase的索引(包括一级索引和多级索引)然后统计出某个key范围内的数据大致占用情况
- 根索引、中间索引只占文件总量的 5% 不到,剩下都是数据部分,而数据不会被扫描到
- 扫描的是 HBase 的 HFile 文件,多个 HFile 之间不相关,并且是只读的
- 通过并行扫描多个文件并汇总统计,可以在几分钟内统计几百G 数据,误差可以控制在 5% 左右

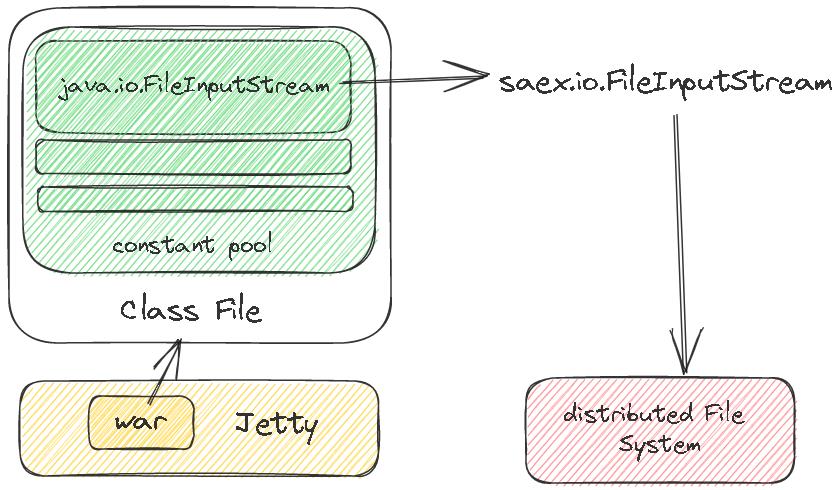
专利 2 原理描述:
- 通过修改class文件常量池中的import类名称
- 比如将java.lang.FileInputStraem 改为了saex.lang.FileInputStream
- 替换后实际调用的是 saex 类,这个类再调用 平台的分布式文件存储
- 这样用户不用修改代码,可以平滑迁移
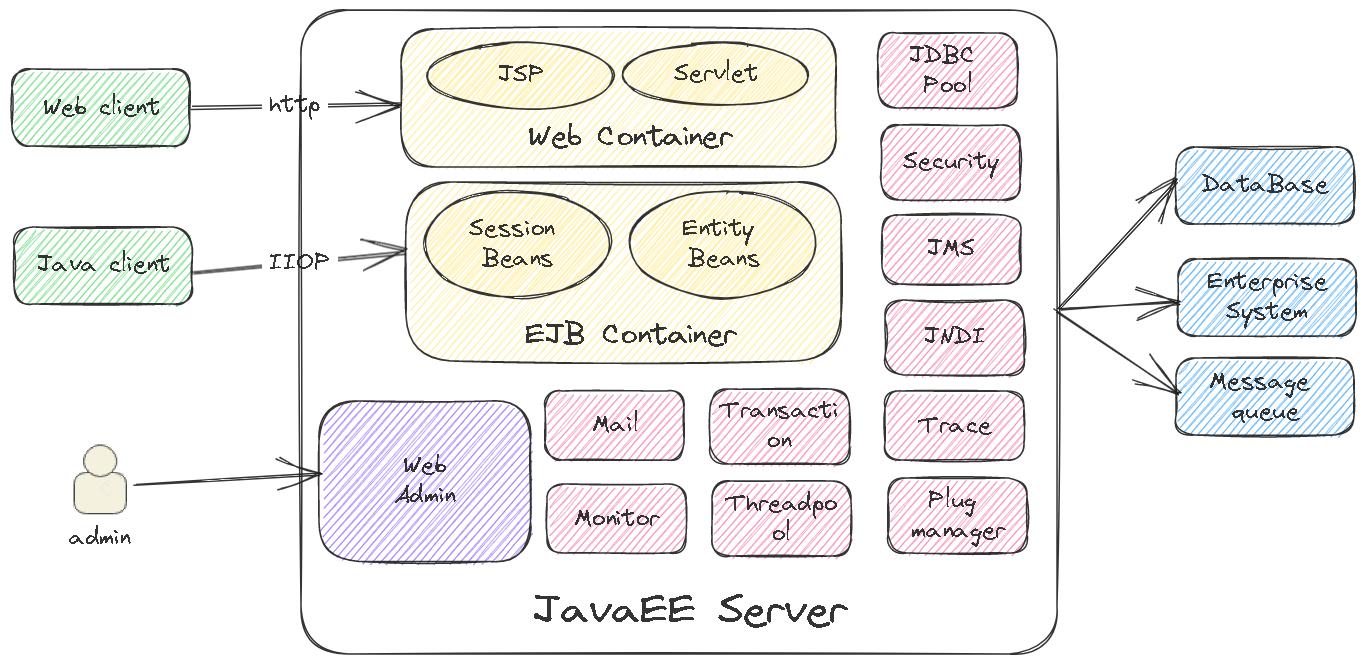
Web中间件
toB 项目,用户主要是县一级的电信、移动
这些企业将他们的 计费系统 就运行在我们的服务器上面
主要工作内容
- 测试选型,基于开源应用服务器做二次开发
- 开发 Web 管理界面,深入研究 Web 模块
产品架构
- Web 容器这个组件类似于 Tomcat、Jetty
- EJB 这个组件现在用的很少,尤其互联网企业几乎不会用,他相当于是现在的 RPC 框架
- 其他的包括 JMS(类似于现在的消息队列)、安全、事务、JNDI,也是应用服务器内很重要的组件
- 最底层的是一套框架支持可插拔组件,用来管理上述的各种大小模块